Keywords: bayesian | normal-normal model | conjugate prior | mcmc engineering | pymc3 | regression | Download Notebook
Contents
%matplotlib inline
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import pandas as pd
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
import seaborn as sns
sns.set_style("whitegrid")
sns.set_context("poster")
The example we use here is described in McElreath’s book, and our discussion mostly follows the one there, in sections 4.3 and 4.4. We have used code from https://github.com/aloctavodia/Statistical-Rethinking-with-Python-and-PyMC3/blob/master/Chp_04.ipynb .
Howell’s data
These are census data for the Dobe area !Kung San (https://en.wikipedia.org/wiki/%C7%83Kung_people). Nancy Howell conducted detailed quantitative studies of this Kalahari foraging population in the 1960s.
df = pd.read_csv('data/Howell1.csv', sep=';', header=0)
df.head()
| height | weight | age | male | |
|---|---|---|---|---|
| 0 | 151.765 | 47.825606 | 63.0 | 1 |
| 1 | 139.700 | 36.485807 | 63.0 | 0 |
| 2 | 136.525 | 31.864838 | 65.0 | 0 |
| 3 | 156.845 | 53.041915 | 41.0 | 1 |
| 4 | 145.415 | 41.276872 | 51.0 | 0 |
df.tail()
| height | weight | age | male | |
|---|---|---|---|---|
| 539 | 145.415 | 31.127751 | 17.0 | 1 |
| 540 | 162.560 | 52.163080 | 31.0 | 1 |
| 541 | 156.210 | 54.062496 | 21.0 | 0 |
| 542 | 71.120 | 8.051258 | 0.0 | 1 |
| 543 | 158.750 | 52.531624 | 68.0 | 1 |
plt.hist(df.height, bins=30);
We get rid of the kids and only look at the heights of the adults.
df2 = df[df.age >= 18]
plt.hist(df2.height, bins=30);
Model for heights
We will now get relatively formal in specifying our models.
We will use a Normal model, $h \sim N(\mu, \sigma)$, and assume that the priors are independent. That is $p(\mu, \sigma) = p(\mu \vert \sigma) p(\sigma) = p(\mu)p(\sigma)$.
Our model is:
\[h \sim N(\mu, \sigma)\\ \mu \sim Normal(148, 20)\\ \sigma \sim Unif(0, 50)\]import pymc3 as pm
A pymc3 model
We now write the model as a pymc3 model. You will notice that the code pretty much follows our formal specification above.
When we were talking about gibbs in a Hierarchical model, we suggested that software uses the Directed Acyclic Graph (DAG) structure of our models to make writing conditionals easy.
This is exactly what pymc does. A “Deterministic Random Variable” is one whose values are determined by its parents, and a “Stochastic Random Variable” has these parental dependencies but is specified by them only upto some sampling.
Deterministic nodes use pm.Deterministic or plain python code, while Stochastics come from distributions, and then belong to the pm.FreeRV
So for example, the likelihood node in the graph below, depends on the mu and sigma nodes as its parents, but is not fully specified by them.
Specifically, a likelihood stochastic is an instance of the ObservedRV class.
A Stochastic always has a logp, the log probability of the variables current value, given that of its parents. Clearly this is needed to do any metropolis stuff! pymc provides this for many distributions, but we can easily add in our own.
with pm.Model() as hm1:
mu = pm.Normal('mu', mu=148, sd=20)#parameter
sigma = pm.Uniform('sigma', lower=0, upper=20)#testval=df2.height.mean()
height = pm.Normal('height', mu=mu, sd=sigma, observed=df2.height)
testval can be used to pass a starting point.
with hm1:
#stepper=pm.Metropolis()
tracehm1=pm.sample(10000)# a start argument could be used here
#as well
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, mu]
Sampling 2 chains: 100%|██████████| 21000/21000 [00:11<00:00, 1885.46draws/s]
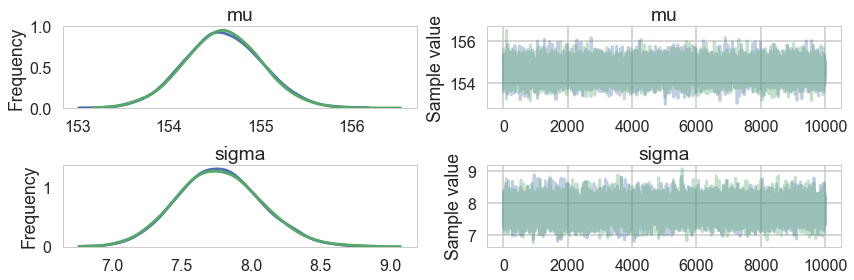
pm.traceplot(tracehm1);
//anaconda/envs/py3l/lib/python3.6/site-packages/matplotlib/axes/_base.py:3449: MatplotlibDeprecationWarning:
The `ymin` argument was deprecated in Matplotlib 3.0 and will be removed in 3.2. Use `bottom` instead.
alternative='`bottom`', obj_type='argument')
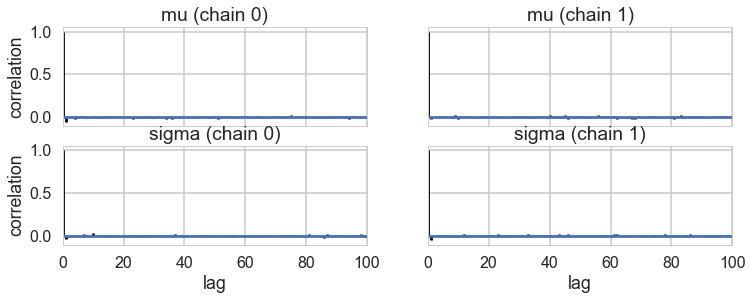
pm.autocorrplot(tracehm1);
pm.summary(tracehm1)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| mu | 154.592303 | 0.417610 | 0.003010 | 153.783429 | 155.435466 | 21645.573326 | 0.999956 |
| sigma | 7.771291 | 0.298118 | 0.001773 | 7.196591 | 8.354221 | 21980.408790 | 0.999954 |
A very nice hack to find the acceptance values is below, which I found at the totally worth reading tutorial here.
tracehm1['mu'][1:]
array([ 153.6004105 , 155.20993936, 154.92823072, ..., 154.32254415,
154.11381157, 155.03932888])
tracehm1['mu'][:-1]
array([ 154.29586399, 153.6004105 , 155.20993936, ..., 154.57722743,
154.32254415, 154.11381157])
def acceptance(trace, paramname):
accept = np.sum(trace[paramname][1:] != trace[paramname][:-1])
return accept/trace[paramname].shape[0]
acceptance(tracehm1, 'mu'), acceptance(tracehm1, 'sigma')
(0.93584999999999996, 0.93584999999999996)
How strong is the prior?
Above we had used a very diffuse value on the prior. But suppose we tamp it down instead, as in the model below.
with pm.Model() as hm1dumb:
mu = pm.Normal('mu', mu=178, sd=0.1)#parameter
sigma = pm.Uniform('sigma', lower=0, upper=50)#testval=df2.height.mean()
height = pm.Normal('height', mu=mu, sd=sigma, observed=df2.height)
with hm1dumb:
#stepper=pm.Metropolis()
tracehm1dumb=pm.sample(10000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, mu]
Sampling 2 chains: 100%|██████████| 21000/21000 [00:11<00:00, 1780.78draws/s]
pm.summary(tracehm1dumb)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| mu | 177.863623 | 0.100933 | 0.000616 | 177.664168 | 178.059976 | 19889.172243 | 0.999951 |
| sigma | 24.610565 | 0.940030 | 0.006250 | 22.824313 | 26.480908 | 20549.336781 | 0.999952 |
Ok, so our mu did not move much from our prior. But see how much larger our sigma became to compensate. One way to think about this is that . 0.1 standard deviation on the posterior corrsponds to a “prior N” of 100 points (1/0.1^2) in contrast to a 20 standard deviation.
Regression: adding a predictor
plt.plot(df2.height, df2.weight, '.');
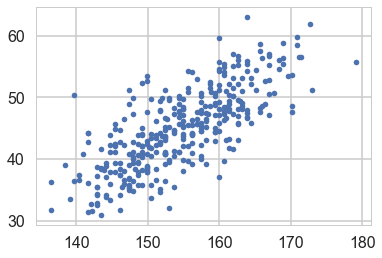
So lets write our model out now:
\[h \sim N(\mu, \sigma)\\ \mu = intercept + slope \times weight\\ intercept \sim N(150, 100)\\ slope \sim N(0, 10)\\ \sigma \sim Unif(0, 50)\]Why should you not use a uniform prior on a slope?
with pm.Model() as hm2:
intercept = pm.Normal('intercept', mu=150, sd=100)
slope = pm.Normal('slope', mu=0, sd=10)
sigma = pm.Uniform('sigma', lower=0, upper=50)
# below is a deterministic
mu = intercept + slope * df2.weight
height = pm.Normal('height', mu=mu, sd=sigma, observed=df2.height)
#stepper=pm.Metropolis()
tracehm2 = pm.sample(10000)#, step=stepper)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, slope, intercept]
Sampling 2 chains: 100%|██████████| 21000/21000 [00:46<00:00, 448.84draws/s]
The acceptance probability does not match the target. It is 0.891475946693, but should be close to 0.8. Try to increase the number of tuning steps.
The $\mu$ now becomes a deterministic node, as it is fully known once we know the slope and intercept.
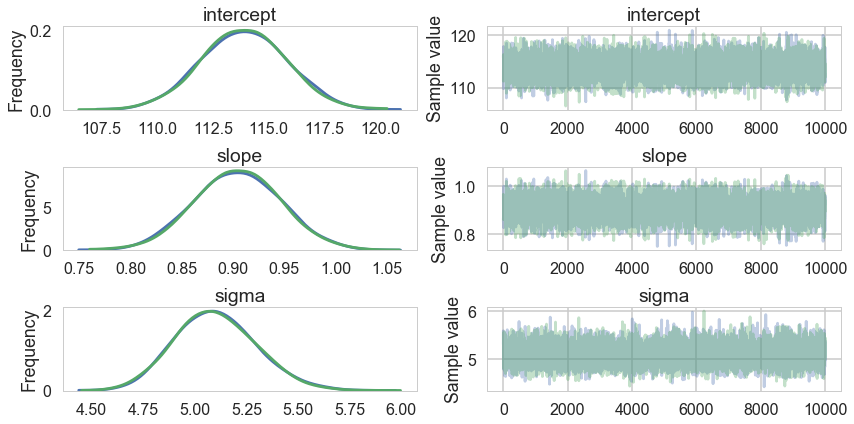
pm.traceplot(tracehm2);
//anaconda/envs/py3l/lib/python3.6/site-packages/matplotlib/axes/_base.py:3449: MatplotlibDeprecationWarning:
The `ymin` argument was deprecated in Matplotlib 3.0 and will be removed in 3.2. Use `bottom` instead.
alternative='`bottom`', obj_type='argument')
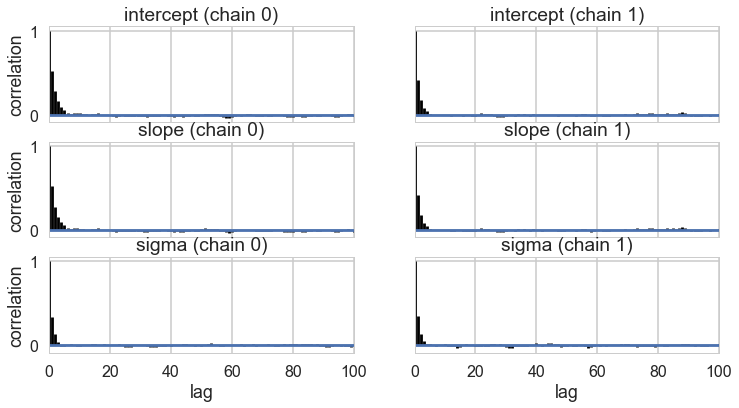
pm.autocorrplot(tracehm2);
acceptance(tracehm2, 'intercept'), acceptance(tracehm2, 'slope'), acceptance(tracehm2, 'sigma')
(0.9819, 0.9819, 0.9819)
Oops, what happened here? Our correlations are horrendous and the traces look awful. Our acceptance rates dont seem to be at fault.
Centering to remove correlation : identifying information in our parameters.
The slope and intercept are very highly correlated:
hm2df=pm.trace_to_dataframe(tracehm2)
hm2df.head()
| intercept | slope | sigma | |
|---|---|---|---|
| 0 | 115.691598 | 0.866668 | 5.307530 |
| 1 | 116.202632 | 0.849961 | 5.589300 |
| 2 | 115.478307 | 0.871079 | 5.464947 |
| 3 | 111.819125 | 0.950337 | 4.797791 |
| 4 | 112.943324 | 0.918542 | 5.034075 |
hm2df.corr()
| intercept | slope | sigma | |
|---|---|---|---|
| intercept | 1.000000 | -0.990003 | -0.002185 |
| slope | -0.990003 | 1.000000 | 0.002087 |
| sigma | -0.002185 | 0.002087 | 1.000000 |
Indeed they are amost perfectly negatively correlated, the intercept compensating for the slope and vice-versa. This means that the two parameters carry the same information, and we have some kind of identifiability problem. We shall see more such problems as this course progresses.
We’ll fix this here by centering our data. Lets subtract the mean of our weight variable.
with pm.Model() as hm2c:
intercept = pm.Normal('intercept', mu=150, sd=100)
slope = pm.Normal('slope', mu=0, sd=10)
sigma = pm.Uniform('sigma', lower=0, upper=50)
# below is a deterministic
#mu = intercept + slope * (df2.weight -df2.weight.mean())
mu = pm.Deterministic('mu', intercept + slope * (df2.weight -df2.weight.mean()))
height = pm.Normal('height', mu=mu, sd=sigma, observed=df2.height)
#stepper=pm.Metropolis()
tracehm2c = pm.sample(10000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma, slope, intercept]
Sampling 2 chains: 100%|██████████| 21000/21000 [00:12<00:00, 1673.38draws/s]
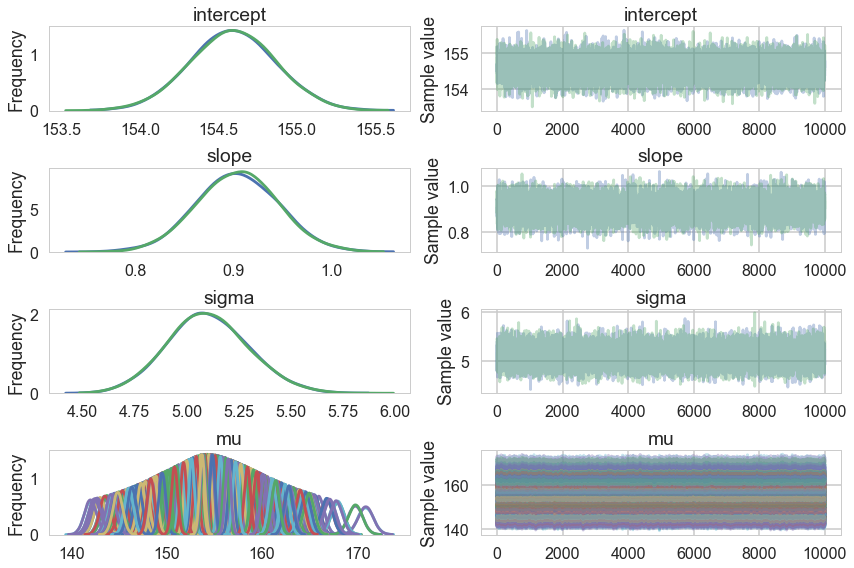
Notice we are now explicitly modelling $\mu$ as a deterministic. This means that it will be added into our traceplots.
pm.traceplot(tracehm2c);
//anaconda/envs/py3l/lib/python3.6/site-packages/matplotlib/axes/_base.py:3449: MatplotlibDeprecationWarning:
The `ymin` argument was deprecated in Matplotlib 3.0 and will be removed in 3.2. Use `bottom` instead.
alternative='`bottom`', obj_type='argument')
pm.autocorrplot(tracehm2c, varnames=['intercept', 'slope', 'sigma']);
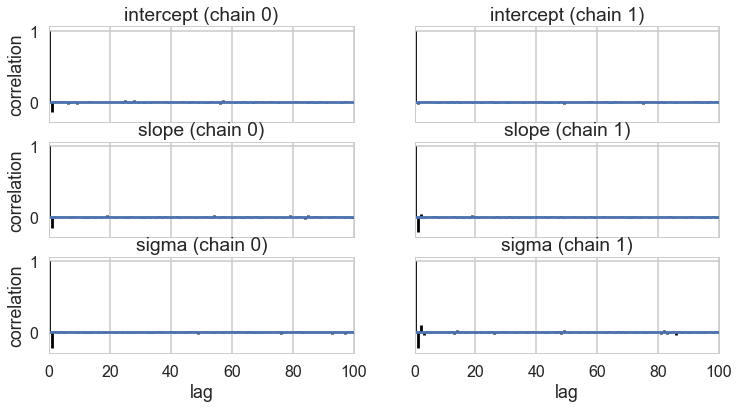
Everything is kosher now! What just happened?
The intercept is now the expected value of the outcome when the predictor is at its mean. This means we have removed any dependence from the baseline value of the predictor.
Posteriors and Predictives
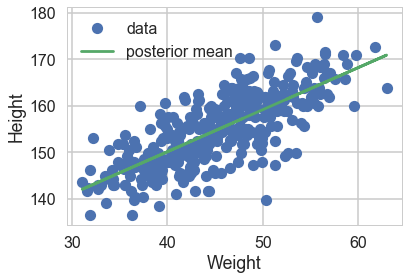
We can now plot the posterior means directly. We take the traces on the $mu$s and find each ones mean, and plot them
plt.plot(df2.weight, df2.height, 'o', label="data")
#plt.plot(df2.weight, tr2c['intercept'].mean() + tr2c['slope'].mean() * (df2.weight - df2.weight.mean()), label="posterior mean")
plt.plot(df2.weight, tracehm2c['mu'].mean(axis=0), label="posterior mean")
plt.xlabel("Weight")
plt.ylabel("Height")
plt.legend();
However, by including the $\mu$ as a deterministic in our traces we only get to see the traces at existing data points. If we want the traces on a grid of weights, we’ll have to explivitly plug in the intercept and slope traces in the regression formula
meanweight = df2.weight.mean()
weightgrid = np.arange(25, 71)
mu_pred = np.zeros((len(weightgrid), 2*len(tracehm2c)))
for i, w in enumerate(weightgrid):
mu_pred[i] = tracehm2c['intercept'] + tracehm2c['slope'] * (w - meanweight)
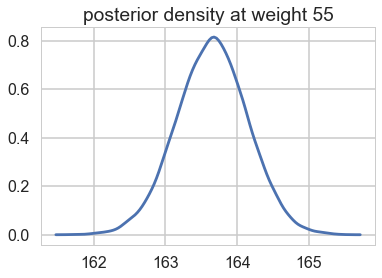
We can see what the posterior density (on $\mu$) looks like at a given x (weight).
sns.kdeplot(mu_pred[30]);
plt.title("posterior density at weight {}".format(weightgrid[30]));
And we can create a plot of the posteriors using the HPD(Highest Posterior density interval) at each point on the grid.
mu_mean = mu_pred.mean(axis=1)
mu_hpd = pm.hpd(mu_pred.T)
plt.scatter(df2.weight, df2.height, c='b', alpha=0.3)
plt.plot(weightgrid, mu_mean, 'r')
plt.fill_between(weightgrid, mu_hpd[:,0], mu_hpd[:,1], color='r', alpha=0.5)
plt.xlabel('weight')
plt.ylabel('height')
plt.xlim([weightgrid[0], weightgrid[-1]]);
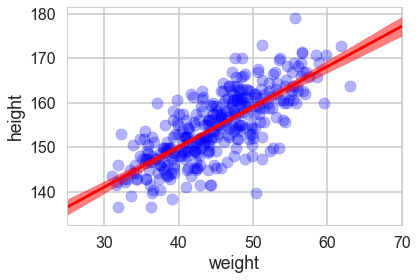
Looks like our posterior $\mu$s are very tight. Why then is there such spread in the data?
hm2c.observed_RVs # these are the likelihoods
[height]
The posterior predictive
Remember that the traces for each $\mu \vert x$ are traces of the “deterministic” parameter $\mu$ at a given x. These are not traces of $y \vert x$s, or heights, but rather, traces of the expected-height at a given x.
Remember that we need to smear the posterior out with the sampling distribution to get the posterior predictive.
pymc3 makes this particularly simple for us, atleast at the points where we have data. We simply use the pm.sample_ppc function
postpred = pm.sample_ppc(tracehm2c, 1000, hm2c)
100%|██████████| 1000/1000 [00:02<00:00, 366.40it/s]
Notice that these are at the 352 points where we have weights.
postpred['height'].shape
(1000, 352)
postpred_means = postpred['height'].mean(axis=0)
postpred_hpd = pm.hpd(postpred['height'])
Now when we plot the posterior predictives, we see that the error bars are much larger.
plt.plot(df2.weight, df2.height, '.', c='b', alpha=0.2)
plt.plot(weightgrid, mu_mean, 'r')
plt.fill_between(weightgrid, mu_hpd[:,0], mu_hpd[:,1], color='r', alpha=0.5)
yerr=[postpred_means - postpred_hpd[:,0], postpred_hpd[:,1] - postpred_means]
plt.errorbar(df2.weight, postpred_means, yerr=yerr, fmt='--.', c='g', alpha=0.1, capthick=3)
plt.xlabel('weight')
plt.ylabel('height')
plt.xlim([weightgrid[0], weightgrid[-1]]);
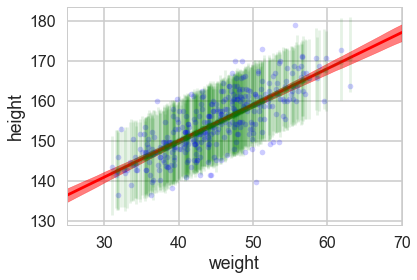
But we would like the posterior predictive at more than those 352 points…so here is the strategy we employ…
If we want 1000 samples (at each x) we, for each such sample, choose one of the posterior samples randomly, with replacement. We then get gridsize mus and one sigma from this posterior, which we then use to sample gridsize $y$’s from the likelihood. This gives us 1000 $\times$ gridsize posterior predictives.
We have seen elsewhere how to do this using theano shared variables.
2*len(tracehm2c)
20000
n_ppredsamps=1000
weightgrid = np.arange(25, 71)
meanweight = df2.weight.mean()
ppc_samples=np.zeros((len(weightgrid), n_ppredsamps))
for j in range(n_ppredsamps):
k=np.random.randint(2*len(tracehm2c))#samples with replacement
musamps = tracehm2c['intercept'][k] + tracehm2c['slope'][k] * (weightgrid - meanweight)
sigmasamp = tracehm2c['sigma'][k]
ppc_samples[:,j] = np.random.normal(musamps, sigmasamp)
ppc_samples_hpd = pm.hpd(ppc_samples.T)
And now we can plot using fill_between.
plt.scatter(df2.weight, df2.height, c='b', alpha=0.9)
plt.plot(weightgrid, mu_mean, 'r')
plt.fill_between(weightgrid, mu_hpd[:,0], mu_hpd[:,1], color='r', alpha=0.5)
plt.fill_between(weightgrid, ppc_samples_hpd[:,0], ppc_samples_hpd[:,1], color='green', alpha=0.2)
plt.xlabel('weight')
plt.ylabel('height')
plt.xlim([weightgrid[0], weightgrid[-1]]);
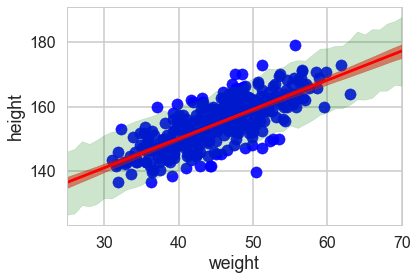
ppc_samples_hpd[-1], ppc_samples_hpd[22]
(array([ 166.50141684, 187.72522616]), array([ 146.2291342 , 165.95145207]))