Download Notebook
Contents
- Collaborators
- Question 1: Rubber Chickens Bawk Bawk!
- Question 2: He Who is Not Courageous Enough to Take Risks Will Accomplish Nothing In Life
- Question 3: Maxwell’s Demon Has a Wonderful Way of showing us What Really Matters
- Q4: Marvel at the DC Flash Light Speed experiment
Harvard University
Fall 2018
Instructors: Rahul Dave
**Due Date: ** Saturday, October 6th, 2018 at 11:59pm
Instructions:
-
Upload your final answers in the form of a Jupyter notebook containing all work to Canvas.
-
Structure your notebook and your work to maximize readability.
Collaborators
** Place the name of everyone who’s submitting this assignment here**
import numpy as np
import scipy.stats
import scipy.special
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
from matplotlib import cm
import pandas as pd
%matplotlib inline
Question 1: Rubber Chickens Bawk Bawk!
In the competitive rubber chicken retail market, the success of a company is built on satisfying the exacting standards of a consumer base with refined and discriminating taste. In particular, customer product reviews are all important. But how should we judge the quality of a product based on customer reviews?
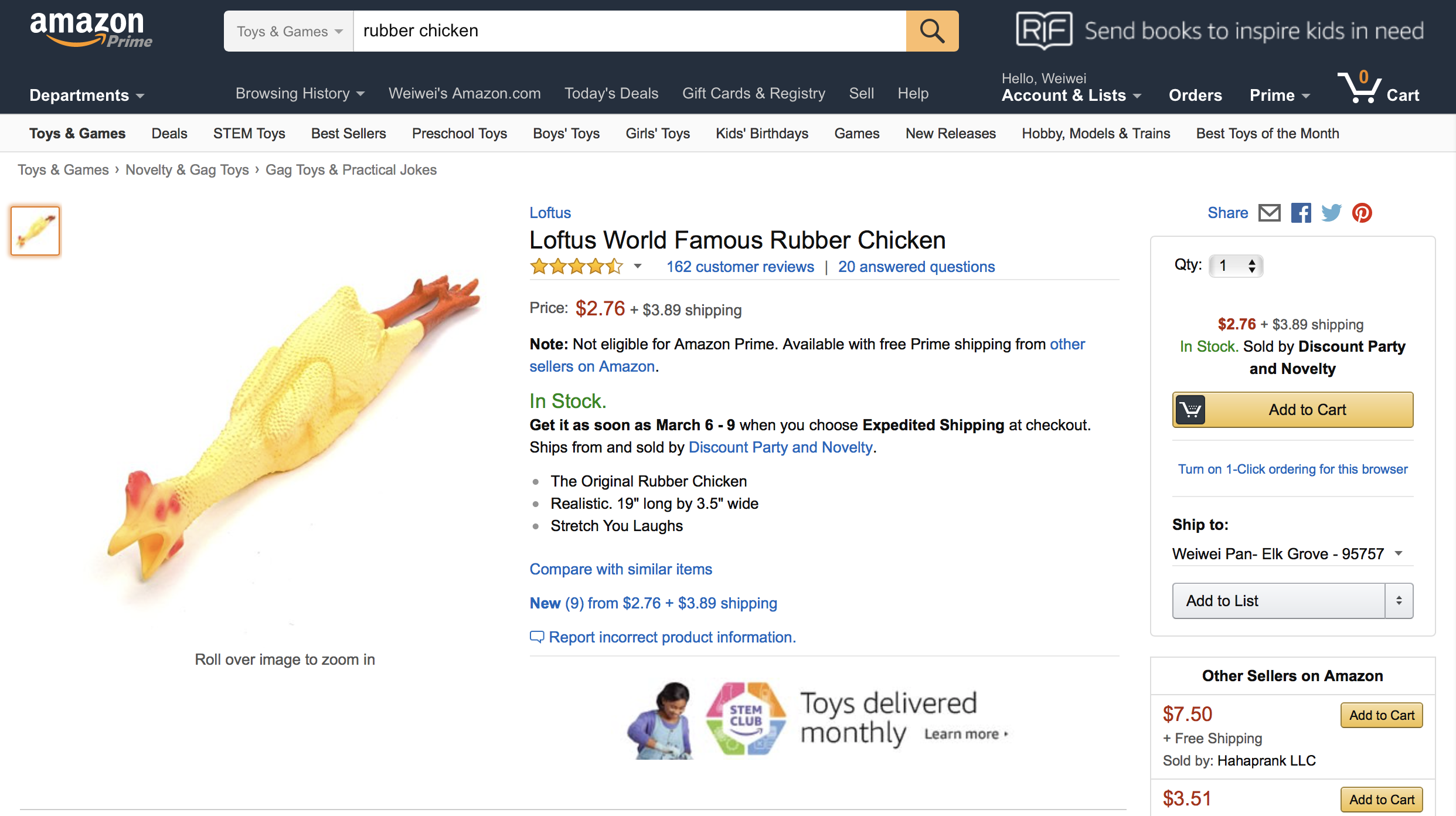
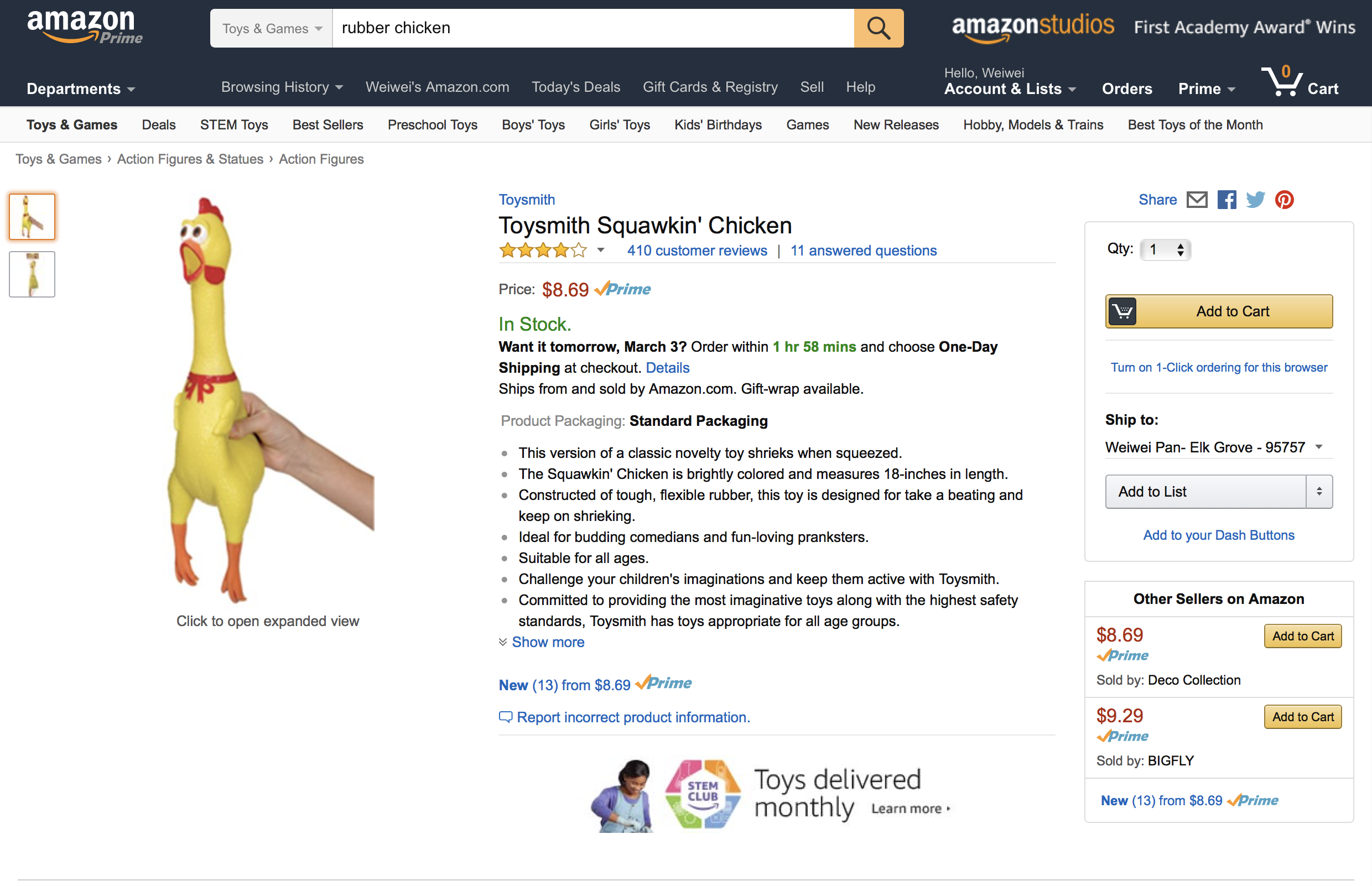
On Amazon, the first customer review statistic displayed for a product is the average rating. The following are the main product pages for two competing rubber chicken products, manufactured by Lotus World and Toysmith respectively:
| Lotus World | Toysmith |
|---|---|
 |
 |
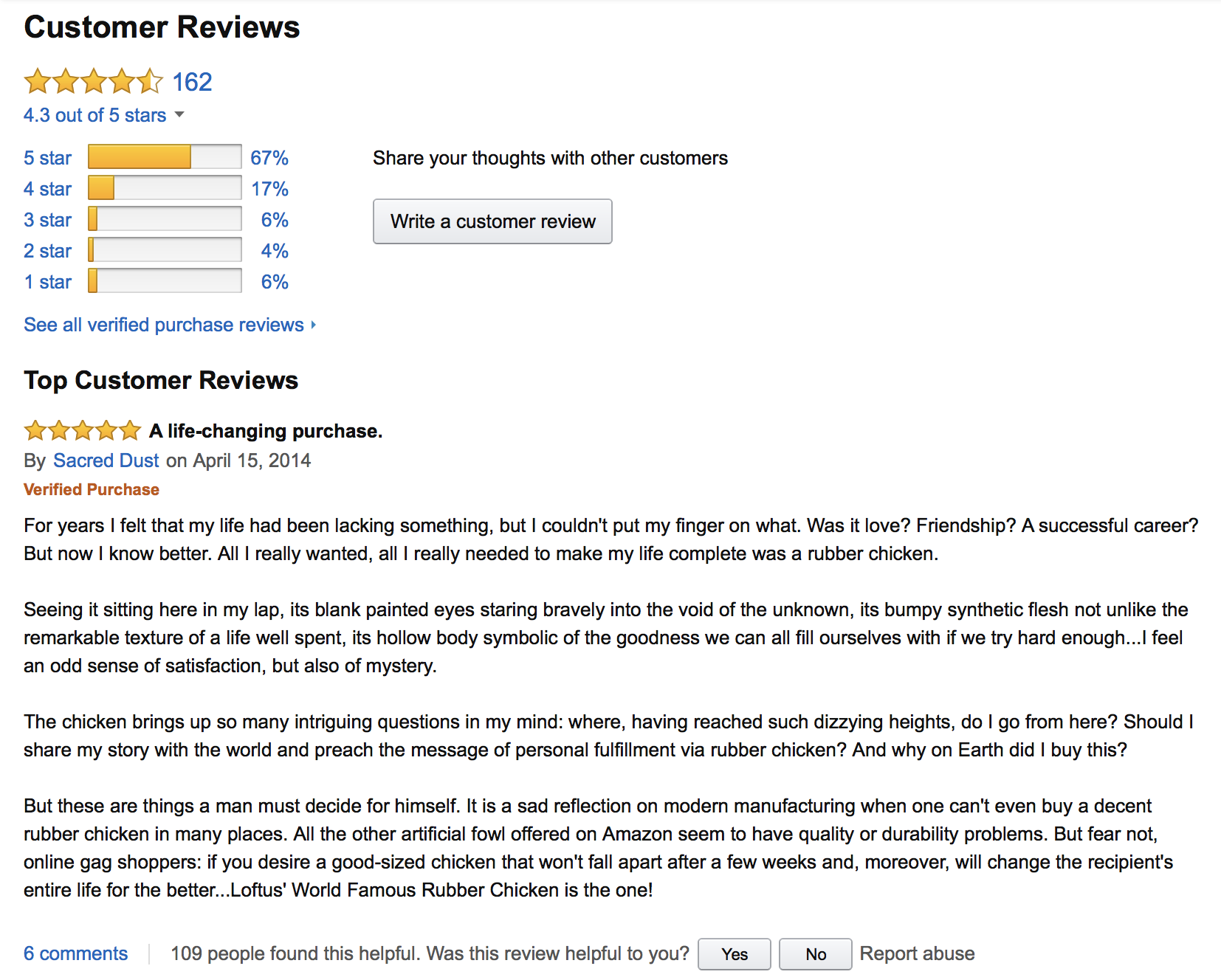
Clicking on the ‘customer review’ link on the product pages takes us to a detailed break-down of the reviews. In particular, we can now see the number of times a product is rated a given rating (between 1 and 5 stars).
| Lotus World | Toysmith |
|---|---|
 |
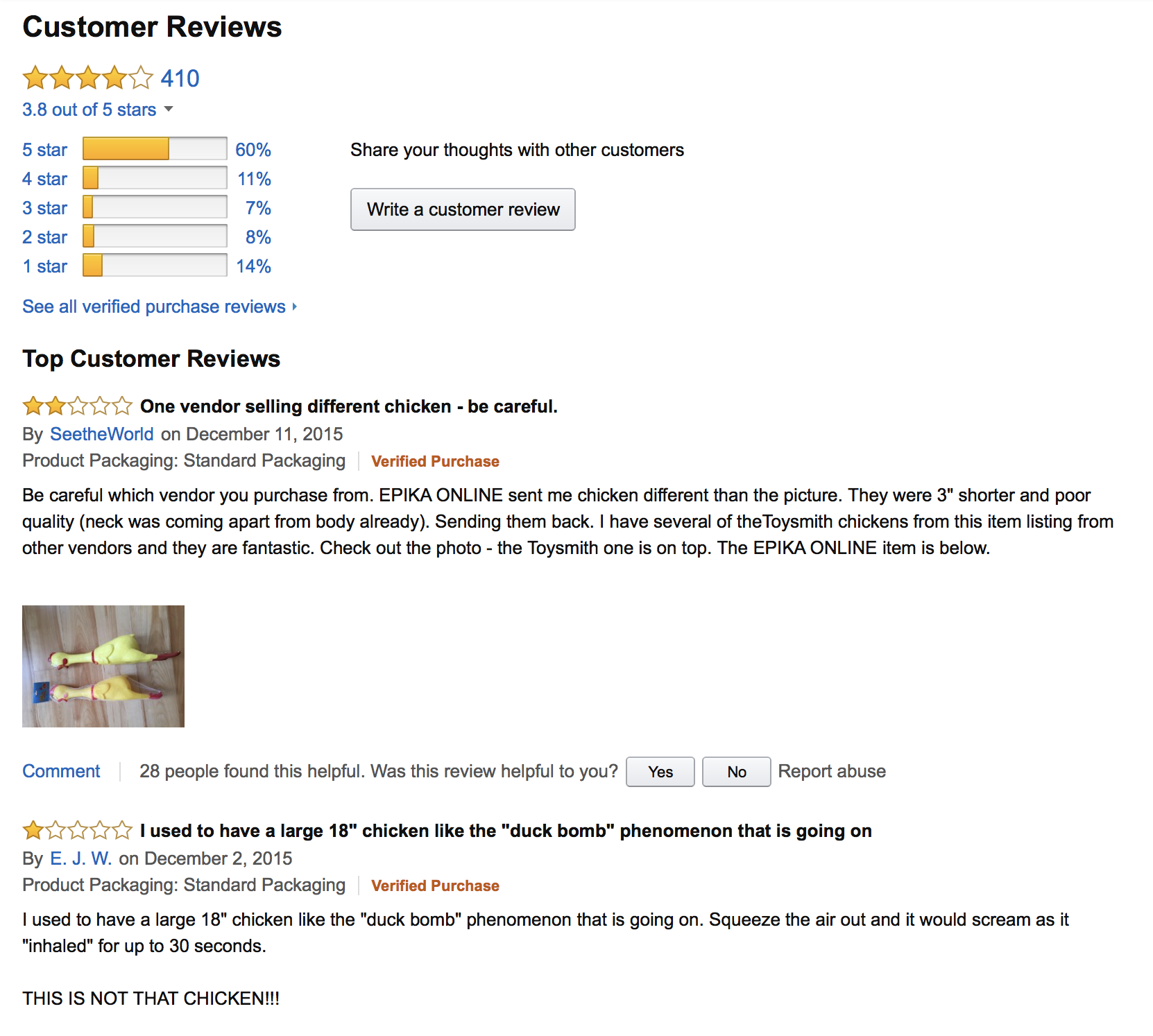 |
(The images above are also included on canvas in case you are offline, see below)
In the following, we will ask you to compare these two products using the various rating statistics. Larger versions of the images are available in the data set accompanying this notebook.
Suppose that for each product, we can model the probability of the value each new rating as the following vector: \(\theta = [\theta_1, \theta_2, \theta_3, \theta_4, \theta_5]\) where $\theta_i$ is the probability that a given customer will give the product $i$ number of stars.
1.1. Suppose you are told that customer opinions are very polarized in the retail world of rubber chickens, that is, most reviews will be 5 stars or 1 stars (with little middle ground). Choose an appropriate Dirichlet prior for $\theta$. Recall that the Dirichlet pdf is given by: \(f_{\Theta}(\theta) = \frac{1}{B(\alpha)} \prod_{i=1}^k \theta_i^{\alpha_i - 1}, \quad B(\alpha) = \frac{\prod_{i=1}^k\Gamma(\alpha_i)}{\Gamma\left(\sum_{i=1}^k\alpha_i\right)},\) where $\theta_i \in (0, 1)$ and $\sum_{i=1}^k \theta_i = 1$, $\alpha_i > 0 $ for $i = 1, \ldots, k$.
1.2. Write an expression for the posterior pdf, using a using a multinomial model for observed ratings. Recall that the multinomial pdf is given by: \(f_{\mathbf{X}\vert \Theta}(\mathbf{x}) = \frac{n!}{x_1! \ldots x_k!} \theta_1^{x_1} \ldots \theta_k^{x_k}\) where $n$ is the total number of trials, $\theta_i$ is the probability of event $i$ and $\sum_i \theta_i = 1$, and $x_i$ is count of outcome $i$ and $\sum_i x_i = n$.
Note: The data you will need in order to define the likelihood function should be read off the image files included in the dataset.
1.3. Sample 1,000 values of $\theta$ from the posterior distribution.
1.4. Sample 1,000 values of $x$ from the posterior predictive distribution.
1.5. Name at least two major potential problems with using only the average customer ratings to compare products.
(Hint: if product 1 has a higher average rating than product 2, can we conclude that product 1 is better liked? If product 1 and product 2 have the same average rating, can we conclude that they are equally good?)
1.6. Using the samples from your posterior distribution, determine which rubber chicken product is superior. Justify your conclusion with sample statistics.
1.7. Using the samples from your posterior predictive distribution, determine which rubber chicken product is superior. Justify your conclusion with sample statistics.
1.8. Finally, which rubber chicken product is superior?
(Note: we’re not looking for “the correct answer” here, any sound decision based on a statistically correct interpretation of your model will be fine)
Question 2: He Who is Not Courageous Enough to Take Risks Will Accomplish Nothing In Life
No Coding required
Consider a setting where the feature and label space are $\mathcal{X} = \mathcal{Y} = [0, 1]$. In this exercise we will consider both the square loss and the absolute loss, namely:
\(\mathbb{l}_{sq}(y_1, y_2) = (y_1 - y_2)^2\) \(\mathbb{l}_{abs}(y_1, y_2) = \left \vert y_1 - y_2 \right \vert\)
Let (X, Y) be random, with the following with joint probability density $p_{XY}(x, y) = 2y$, where $x, y \ \in \ [0, 1]$. We define statistical risk as follows:
Definition (Statistical Risk) For a prediction rule $f$ and a joint distribution of features and labels $P_{XY}$ the statistical risk $\mathcal{R}(f)$ of $f$ is defined as
\(\mathcal{R}(f) \equiv \mathbb{E}_{XY}\left[\mathbb{l}(f(X),Y)\ \vert \ f \right]\),
where $(X, Y) \sim P_{XY}$. The conditional statement ensures the definition is sensible even if $f$ is a random quantity.
2.1. Show that in this case $X$ and $Y$ are independent, meaning the feature $X$ carries no information about Y.
2.2. What is the risk of prediction rule $f(x) = \frac{1}{2}$ according to the two loss functions?
2.3. What is the risk of the prediction rule $f^*(x) = \frac{1}{\sqrt{2}}$ according to the two loss functions?
2.4. Show that $f^*$ has actually the smallest absolute loss risk among all prediction rules.
Hint (for 2.3):
* In general the Bayes predictor according to the absolute value loss is the median of the conditional distribution of $Y$ given $X = x$.
Question 3: Maxwell’s Demon Has a Wonderful Way of showing us What Really Matters
Some Coding required
3.1. Find the entropy of the exponential probability density on support (0, $\infty$) with mean $\lambda$.
3.2. Show that the exponential distribution $p^$ is the maximum entropy distribution on support (0, $\infty$) with specified mean $\lambda$. That is to say prove that for any continuous probability density function $p(x)$ on (0, $\infty$) with mean $\lambda$ then the entropy h(p) <= h($p^$) with equality if and only if p is also the exponential with mean $\lambda$
We’re familiar with the CLT as a way of approximating the sum of IID random variables with an appropriate Normal distribution. Let’s investigate this relationship by using the KL-Divergence. Given n identically distributed Bernoulli variables $Y_i \sim Bern(p)$, then their sum approaches a Normal distribution.
3.3. Visualize this relationship by drawing n = 10,000 samples from a Bernoulli with p = 0.02. These samples determine a random variable and thus a probability distribution (which in the last homework we called the empirical distribution of the data). Visualize this probability distribution by plotting a normed histogram of the samples. On your plot overlay the appropriately fitted Gaussian distribution. Make sure to appropriately title and label your plot.
3.4. From visual inspection are the two distributions close to each other?
3.5. Formalize your answer to 3.3 and 3.4 by writing a program to compute the K-L divergence between the two distributions (the sum of 10000 sampled Bernoullis and the appropriate Gaussian). What is the value of the KL divergence.
3.6. Let’s visualize the convergence of the sum of bernoulli RVs to a Gaussian as fortold by the CLT by repeating the process from 3.5 for various values of n. We’ll set our selection of sample sizes to the following: [100, 250, 500, 750, 1000, 2500, 5000, 7500, 10000, 50000, 100000]. Setting n to each of the specified sample sizes repeat the following procedure 10 times:
- Draw n bernoulli samples using the Bernoulli parameter from 3.3 (p=0.02).
- Calculate the Kullback-Leibler divergence between the random variable defined by the sum of Bernoullis samples and the appropriately fitted gaussian.
For each sample size you should have 10 KL divergences. Construct a log scale (in both axes) plot of the Kullback-Leibler divergence and and the 3-$\sigma$ envelope against the sample size. What can you convergence of the distributions in question? What does this mean for the CLT?
Q4: Marvel at the DC Flash Light Speed experiment
Simon Newcomb did an experiment in 1882 to measure the speed of light. These are the times required for light to travel 7442 metres. These are recorded as deviations from 24,800 nanoseconds.
This data is in the following dataset $D$.
light_speed = np.array([28, 26, 33, 24, 34, -44, 27, 16, 40, -2, 29, 22, 24, 21, 25,
30, 23, 29, 31, 19, 24, 20, 36, 32, 36, 28, 25, 21, 28, 29,
37, 25, 28, 26, 30, 32, 36, 26, 30, 22, 36, 23, 27, 27, 28,
27, 31, 27, 26, 33, 26, 32, 32, 24, 39, 28, 24, 25, 32, 25,
29, 27, 28, 29, 16, 23])
4.1. Plot a histogram of the data. Are there outliers in the data? What data points might you consider to be outliers?
4.2. We use a normal models with weakly informative priors to model this experiment. In particular assume uniform priors for both $\mu$ and $\sigma$:
\[\mu \sim Uniform(0, 60)\] \[\sigma \sim Uniform(0.1, 50)\]Write down an expression for the posterior (joint) pdf $p(\mu, \sigma \vert D)$.
4.3. Set up a 500 point grid in both the $\mu$ space and the $\sigma$ space. Compute the normalized posterior on this grid and make a contour plot of it.
Hint: np.meshgrid is your friend
4.4. Use this normalized posterior to sample from the grid, posterior samples of size 500000. That is the posterior should be of shape (500000, 2). (Hint: one way to do it is to first flatten the meshgrid into a grid of shape (250000, 2). Flatten the posterior probabilities as well into a size 250000 vector. Then sample 500000 indices and use them to index the grid). Plot the $\mu$ and $\sigma$ marginal posteriors.
4.5. Experiment with reducing the grid size down to 100x100. How do the marginal posteriors now look? What does this look tell us about the dimensional scaling of this grid-sampling-in-proportion-to-posterior method of obtaining samples?
4.6. Now draw from the data sampling normal distribution to obtain the posterior-predictive distribution. You will have as many samples as the size of the posterior. Plot the posterior predictive distribution against the data, and write down your observations.
4.7. Informally using a test-statistic
We might wish to compute a test statistic from the posterior predictive. Say for example, we wish to talk about the minimum value of the posterior predictive.
The way to do this is to replicate the posterior predictive multiple times. We replicate the posterior-predictive (that is, do the sampling you did in 4.6) 66 times, which is the size of our dataset. In other words, we create as-many artificial datasets as there are samples in our posterior.
This is called a replicative posterior predictive.
Compute the replicative distribution of the minimum-value of the dataset and compare it to the actual value. What might you conclude about the quality of the specification of our model for the purposes of computing minimum values?